据港交所1月27日披露,北京星辰天合科技股份有限公司(简称“星辰天合”)向港交所主板递交上市申请书。
星辰天合专注于提供企业级AI存储解决方案,助力企业大规模高效整合数据、决策及运营。两类主要解决方案,即AI数据湖存储与AI训推存储解决方案,实现AI存储在企业客户业务运营中的无缝部署及实施,解决企业在AI转型过程中的关键存储需求。
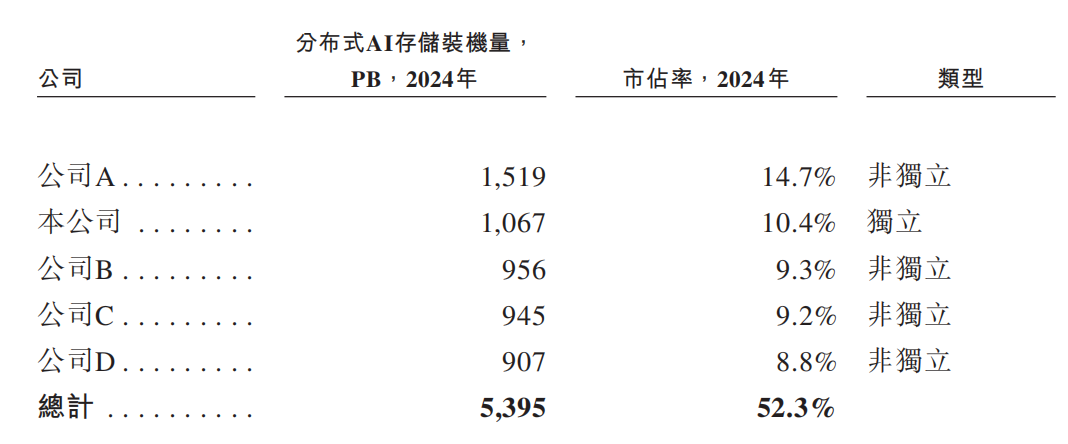
根据灼识咨询的资料,按2024年装机量计,中国前五大分布式AI存储解决方案提供商合计市占率为52.3%,星辰天合占市场的10.4%。是中国第二大的分布式AI存储解决方案提供商及最大的独立分布式AI存储解决方案提供商。
于2023年、2024年以及截至2024年及2025年9月30日止九个月,公司的收入分别为人民币166.8百万元、人民币172.5百万元、人民币117.8百万元及人民币194.9百万元。2023年、2024年以及截至2024年9月30日止九个月,公司分别录得净亏损人民币180.7百万元、人民币84.2百万元及人民币65.5百万元。截至2025年9月30日止九个月,公司录得净利润人民币8.1百万元。
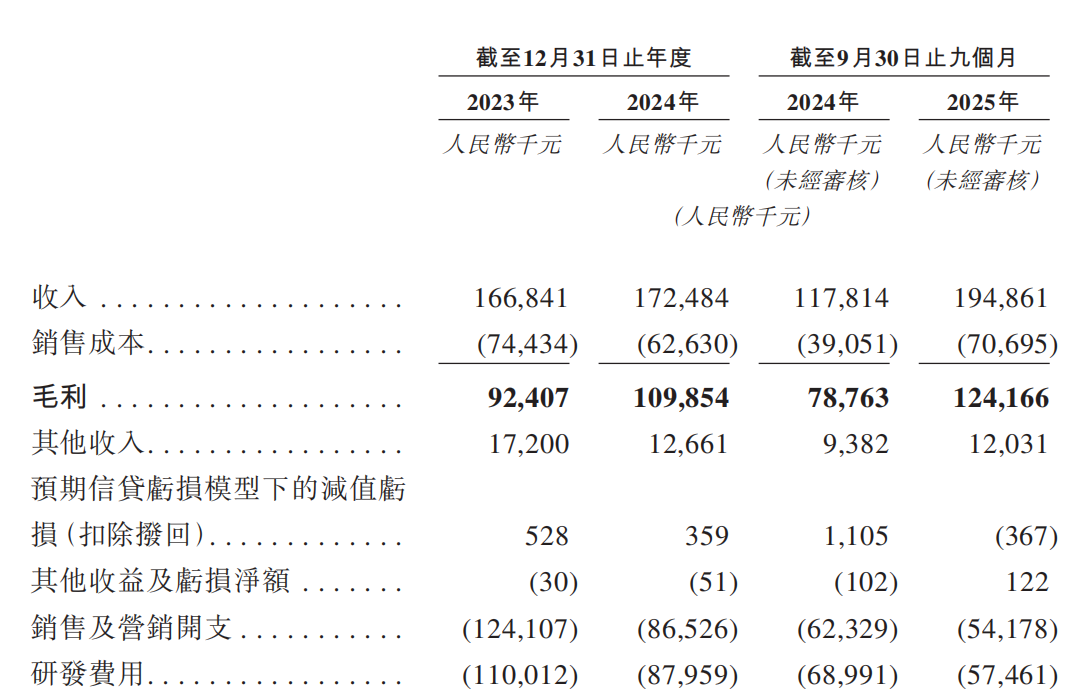
截至2023年及2024年12月31日以及截至2025年9月30日止九个月,研发团队分别由156名、133名及125名成员组成,分别占同期员工总数的43.4%、42%及40.8%。于2023年及2024年以及截至2024年及2025年9月30日止九个月,公司的研发费用分别为人民币110.0百万元、人民币88.0百万元、人民币69.0百万元及人民币57.5百万元,分别占各自期间总收入的65.9%、51.0%、58.6%及29.5%。
产品
AI数据湖存储解决方案旨在将海量原始非结构化数据(例如图像、视频和文档)整合、清洗和保存到一个集中式存储库中以供长期使用。作为AI数据生命周期的起点,其在数据用于模型开发前收集、组织及管理数据。
AI训推存储解决方案旨在高速地向高性能计算资源(例如GPU集群)提供数据。通过提供持续的实时响应能力,其支持AI管线中对性能要求最高的阶段 - 模型训练(需要快速访问大型数据集和频繁的检查点)和推理(需要快速检索和更新上下文数据)。
公司的核心技术栈专为AI时代的数据基础设施而打造,并构成公司的差异化产品能力的基础。
星海架构:用于全闪存数据中心的分布式存储架构。星海架构(XSKY极速全共享架构)是一种分布式存储架构,旨在解决行业从SATA/SAS演进至NVMe时,SSD介质时延下降至微秒级的性能瓶颈,从而充分挥现代全闪存系统的性能。
XScale:AI与多云时代的核心存储引擎。XScale是公司的自有核心存储引擎,旨在支持EB级非结构化数据、混合云协作及AI驱动的数据湖架构。 XScale的主要能力包括独立元数据扩展,单桶支持上千亿个对象,小文件聚合技术,智能接入加速,企业级服务质量,及多云协作和生命周期管理。
主要研究主题及当前项目方向包括XPFS和AIMesh。其中,XPFS旨在通过构建高吞吐量、低延迟且高度并发的数据访问层提供超高性能数据访问与统一的多协议支持,并将作为MeshFS和MeshFusion 产品的核心技术基础。
AIMesh为公司特专科技产品的一部分,并设计为一个横跨公司的AI数据湖存储及AI训推存储解决方案的统一软件定义层,当中包括以下组合:MeshFS,用于AI训练的高速数据层,旨在克服I/O围墙瓶颈;MeshFusion,推理记忆层扩展了大型上下文AI应用程序的存储器容量;及MeshSpace,管理和移动海量数据集的全球AI数据湖。这些组合共同构成AIMesh,一个将各种资源连接到一致的软件定义系统的平台。公司已于2021年1月推出MeshFS、MeshFusion及MeshSpace。
凭借在分布式存储领域的丰富经验,深度整合了计算、网络和多协议存储能力,开发出一系列一体机。产品线涵盖X3000/X5000一体机及基于本土处理器的Y3000/Y5000一体机,为追求可靠可扩展数据基础设施的客户提供预配置即开即用的部署方案。每款设备均支持全系列AI数据湖存储解决方案,以及AI训推存储解决方案。
3000系列设备专为高性能工作负载优化设计。5000系列设备则针对容量导向型场景打造。X系列是面向主流企业环境的标准非本土化产品线,而Y系列则是本土化生态版本,确保与本土CPU、操作系统及信任堆栈组件完全兼容。

客户
截至2024年12月31日,根据灼识咨询的资料,按2024年收入计,公司的客户基础涵盖了中国的前五大液晶面板制造商中的3家、前十大动力电池制造商中的3家、前三大光伏制造商中的2家;在金融领域,根据灼识咨询的资料,按2024年收入计,公司的客户基础涵盖了中国的12家股份制银行中的4家、33家万亿资产规模银行中的11家(截至2024年12月31日)及前十大寿险公司中的4家。
截至2025年9月30日止九个月,公司的整体净收入留存率达141.3%,显示出高度的客户黏性和满意度。公司在自动驾驶、大型模型训练、工业AI和金融科技等核心AI应用领域实现了大规模商业部署。例如,在自动驾驶领域,公司支持从生产线存储到研发和路测数据处理的完整流程。在大模型训练领域,公司为数千至数万个GPU的集群提供高性能文件系统和混合云数据流动能力。在工业AI领域,公司深度嵌入头部面板和半导体客户的核心生产流程。在金融科技领域,公司助力构建私有化知识库和企业级数据湖,推动智能化转型。
市场规模
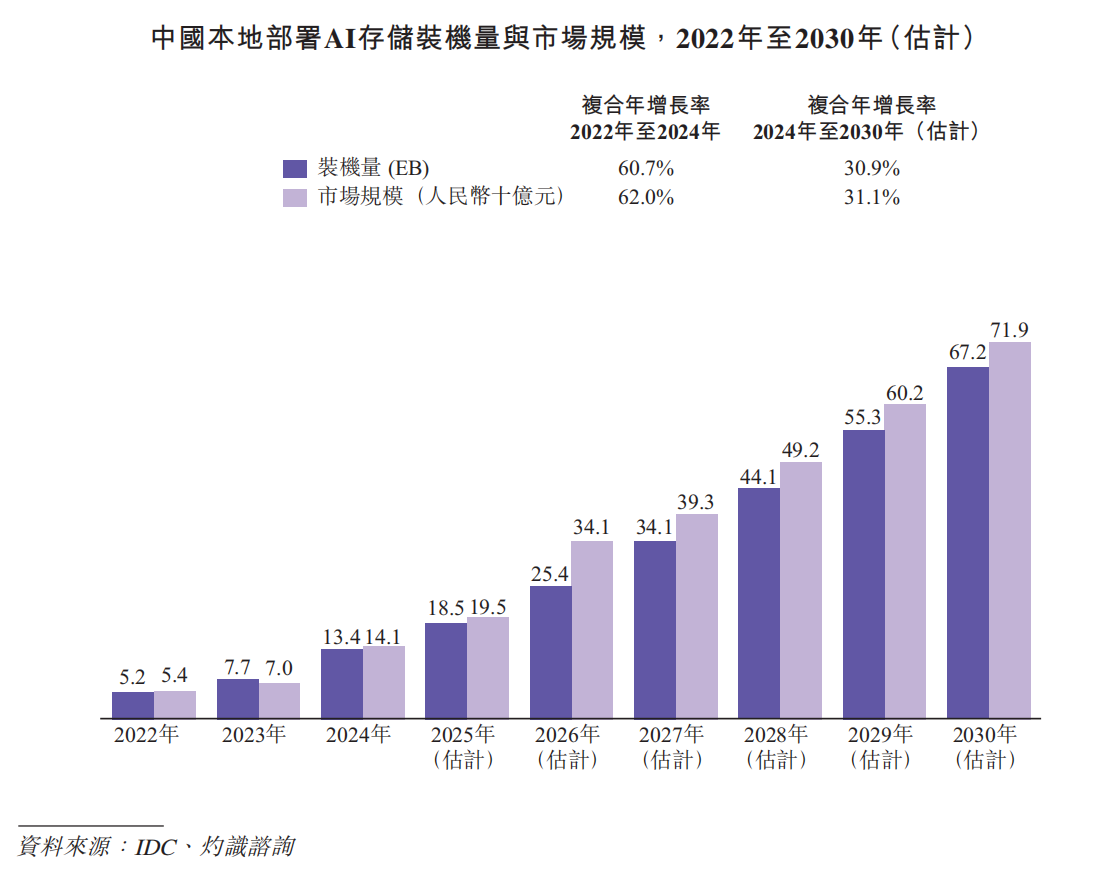
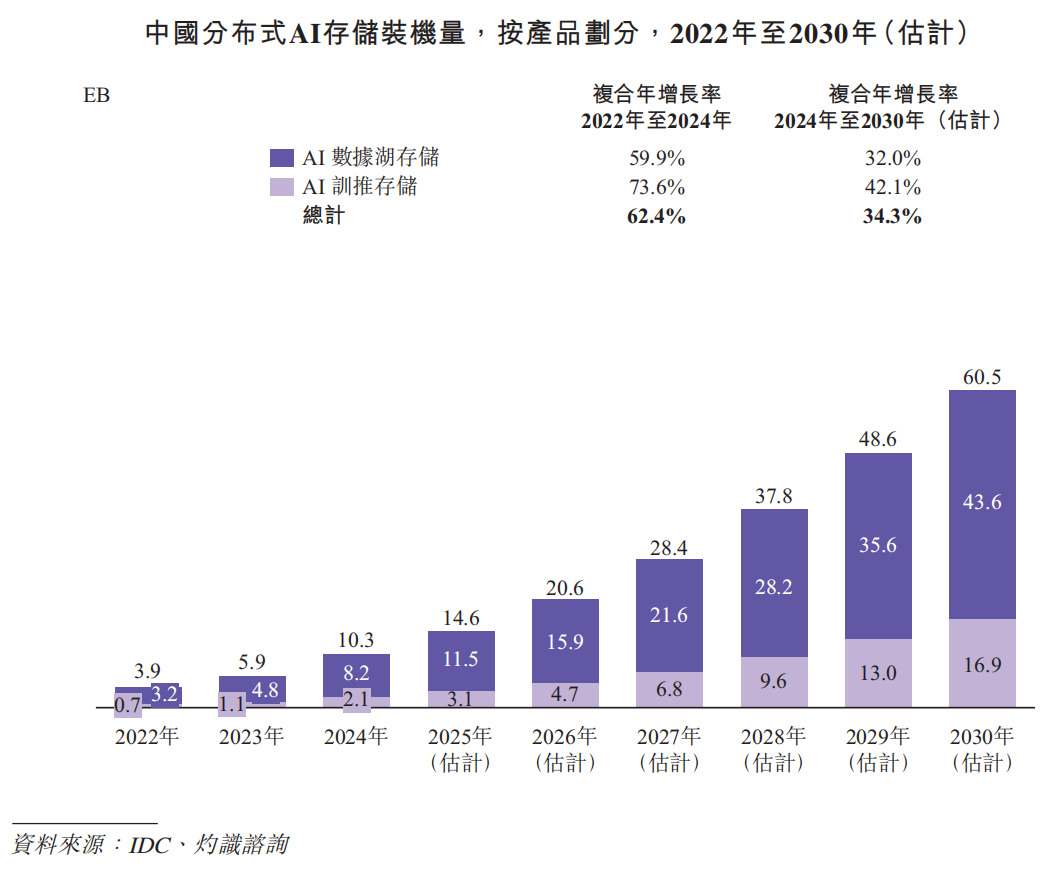
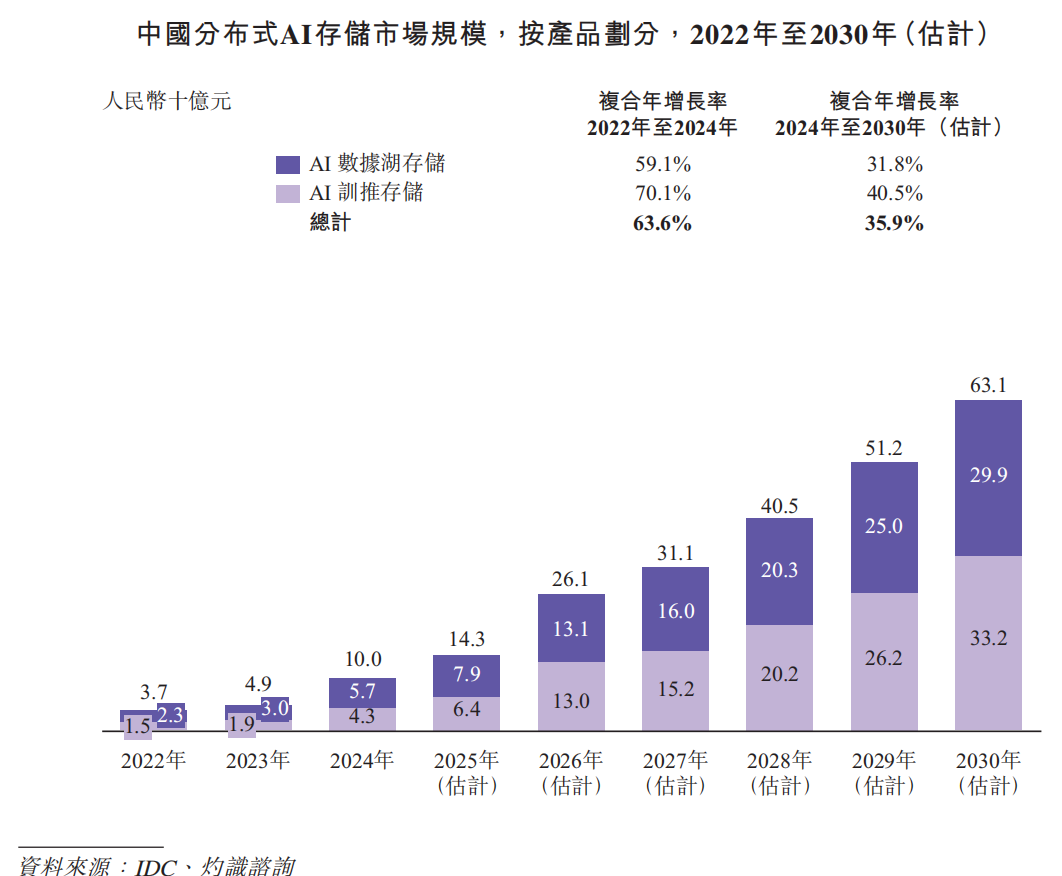
根据灼识咨询的资料,中国AI基础设施市场规模在2024年达到人民币2,176亿元,占全球AI基础设施市场约15%。预计市场规模将在2030年扩大至人民币10,991亿元,复合年增长率为31.0%,预测届时中国在全球市场的占比将上升至约25%。其中,预计本地部署AI基础设施市场规模将从2024年的人民币1,088亿元增长至2030年的人民币5,770亿元,复合年增长率为32.1%。中国分布式AI存储市场规模按收入计在2024年达到人民币100亿元,并预计在2030年增长至人民币631亿元。中国分布式AI存储装机量在2024年达到10.3EB,并预计在2030年扩大至60.5EB,复合年增长率为34.3%。
于2024年,AI数据湖存储占市场的约80%,而AI训推存储占20%。预计以上占比将于2030年分别转为约72%及28%。按分布式AI存储装机量计,2024年中国五大供应商合计持有市场份额的52.3%。按2024年分布式AI存储装机量计,公司是中国第二大分布式AI存储供应商,也是最大的独立供应商。
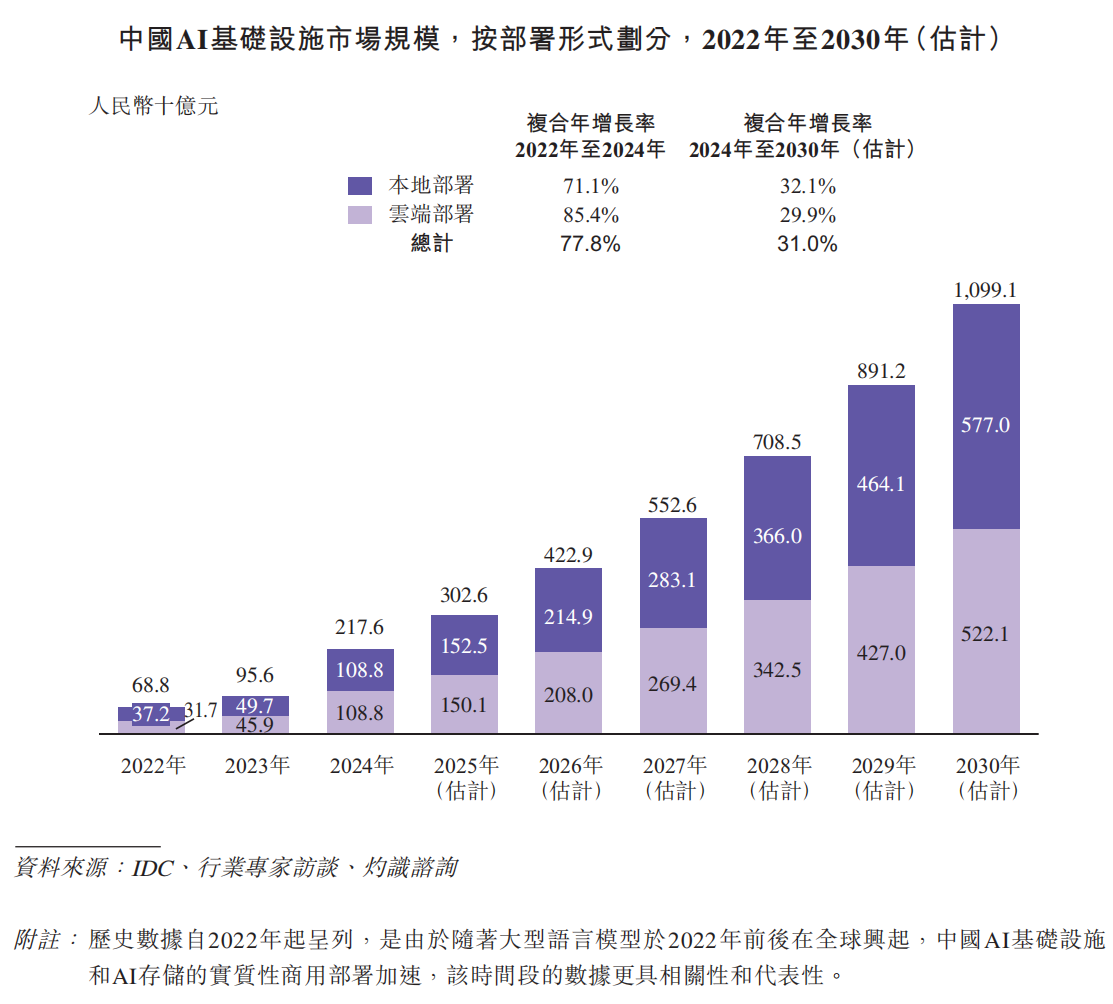
根据灼识咨询的资料,中国本地部署AI存储装机量在2024年达到13.4EB,并预计在2030年扩大至67.2EB,复合年增长率为30.9%。同时,中国本地部署AI存储市场规模在2024年达到人民币141亿元,并预计在2030年增长至人民币719亿元,复合年增长率为31.1%。
AI训练和推理的挑战
训练侧的「I/O墙」。目前主流的大模型参数规模普遍达到十亿以上,训练集群通常有上千乃至上万块AI芯片在同时工作。训练过程需要AI芯片不断读取海量数据、并定期保存模型快照(checkpoint),产生短时间内的巨大读写压力。同时,训练期间会有大量小文件被随机访问,显著增加存储系统的管理和响应负担。传统存储难以支撑这种高强度并发访问,容易导致AI芯片长时间闲置等待数据,整体训练效率大幅下降。
推理侧的「内存墙」。更长的上下文和更复杂的交互,是大模型的一大发展趋势。为了支持这些特性,大模型需要保留大量中间计算结果作为缓存,而缓存通常存放在AI芯片的显存中,来保证其能被高速读写。未来,可以预见这部分缓存的规模将迅速膨胀,远超AI芯片的显存容量,而传统存储系统不具备媲美缓存的高速读写性能,因此企业不得不为显存而继续采购昂贵的AI芯片,导致推理成本仍有极大的优化空间。
数据侧的「重力墙」。企业的数据往往分散在不同系统中,原始数据可能在大容量的存储系统中里,而训练又需要高读写性能的存储支撑。数据在这些系统之间迁移耗时长、成本高,还容易造成数据孤岛和版本混乱的问题。
分布式存储
作为外存,可与AI芯片显存、内存共同形成多级缓存架构,可随集群规模扩展缓存容量与带宽,适配推理的高并发小文件读写。适用于大规模AI训练、多集群推理、RAG数据湖、矢量数据库、KV Cache、企业级AI平台。
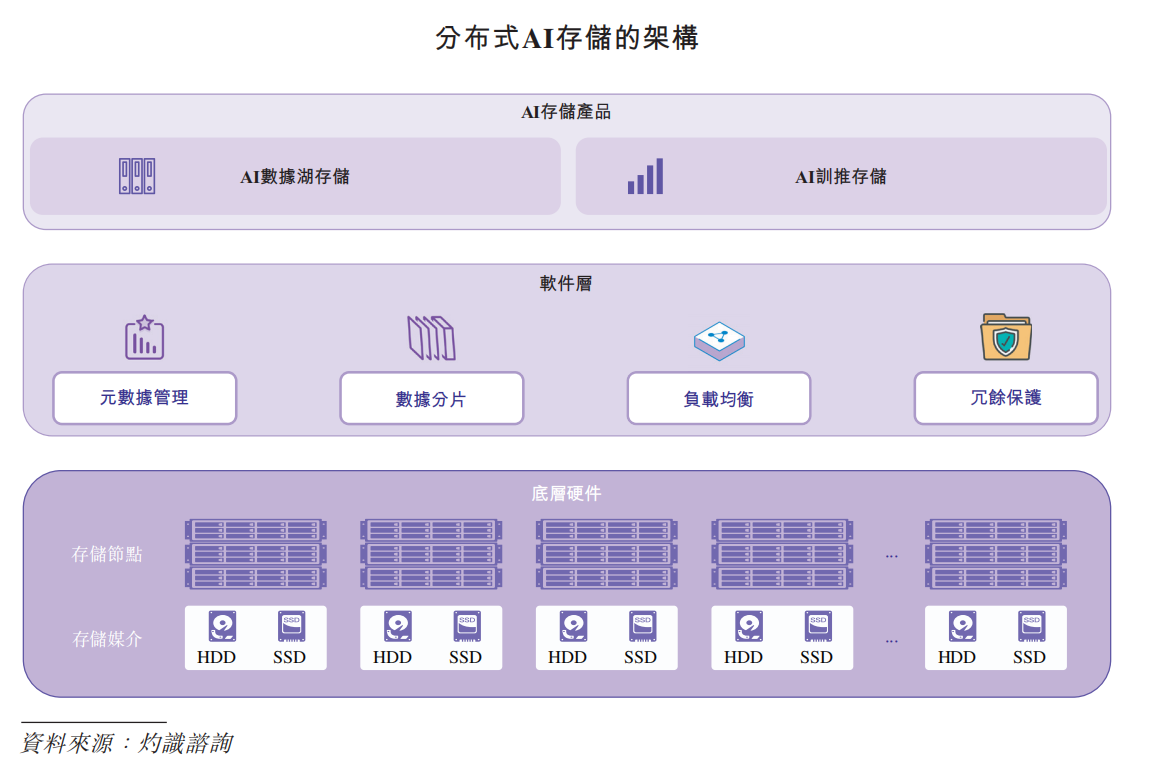
分布式AI存储的产品根据任务需求可分为两类:AI数据湖存储和AI训推存储。
AI数据湖存储主要面向AI生命周期中长期留存的温、冷数据,如训练样本归档、历史模型版本、日志数据及中间特征文件等。此类系统强调高容量密度、成本效率与数据可靠性,通过分层存储、压缩编码与副本冗余技术实现低成本的数据持久化。
其部署规模通常与整体数据资产规模直接挂钩。对于拥有海量数据资源的客户,AI数据湖存储构成其数据湖与知识库体系的底座,用于支撑长期的数据积累与治理。系统性能指标以容量利用率、存储成本、数据恢复可靠性等为核心。
AI训推存储聚焦AI计算阶段对热数据的高并发访问需求,是模型训练与推理性能释放的关键环节。其系统架构通常采用高带宽互联、分布式文件系统与数据分片机制,以实现高吞吐、低延迟、强一致性的访问体验。
与AI数据湖存储不同,AI训推存储是AI基础设施中与算力最紧密耦合的系统,其部署规模与AI算力规模高度相关,强调数据局部性与算存协同优化,常与AI集群的高速网络深度绑定,以减少数据传输瓶颈。
根据灼识咨询,中国分布式AI存储装机量在2024年达到10.3EB,并预计在2030年扩大至60.5EB,复合年增长率为34.3%。于2024年,AI数据湖存储占市场的约80%,而AI训推存储占20%。预计以上占比将于2030年分别转为约72%及28%。
同时,根据同一资料来源,中国分布式AI存储市场按收入计在2024年达到人民币100亿元,并预计在2030年增长至人民币631亿元。
根据灼识咨询的资料,按2024年装机量计,中国五大分布式AI存储解决方案供应商合计持有市场份额的52.3%。按2024年装机量计,公司是中国第二大分布式AI存储解决方案供应商,也是最大独立解决方案供应商,市场份额为10.4%。

公司构建了一个生态系统,集成平台的高性能与开放标准的灵活性相结合,并建 立了一个生态系统壁垒,而公司认为该壁垒是行业新进入者难以复制的。
适配多算力体系:公司的AI存储解决方案可与不同类型的计算芯片无缝协 作,例如Nvidia、Hygon和Ascend。这种灵活性深受客户重视,因为客户经常使用来自不同供应商的混合硬件。公司的技术提供了一个中性、面向未来的存储底座,支持各种计算环境,无需将客户锁定在单一供应商。
云原生与主权:公司的解决方案可与云原生环境无缝集成,同时确保数据完全由客户掌控。这对于智能制造及金融机构等受监管行业至关重要。客户可在本地获得类似云的敏捷性和可扩展性,而无需牺牲安全性或合规性。
行业生态协作:公司与市场主流计算生态伙伴紧密合作,公司的产品能够与Intel、AMD等主流架构顺畅适配,具备良好的兼容性和可扩展性,使公司的高性能存储系统能够自然融入多样化的计算环境,支持高性能数据分析等核心工作负荷,并提升客户整体的数据处理效率。